When did everything ML get 'deep'? Using fasttext to examine semantic trends in 30 years of NIPS papers
July 16, 2018
So, you’re an aspiring machine learning researcher clawing your way up to publication respectability. You think to yourself, what’s the coolest topic I could be doing research on?
Sure, you could figure out the landscape by reading all 7,241 papers published over the last 30 years at the Conference on Neural Information Processing, more popularly known as NIPS (think of it as the Met Gala for AI and ML nerds) but that would take you 6,035 hours to read if you can read as fast as the average human. That’s 251 days of nonstop reading. But what if there was a way to let machine learning do some heavy lifting for you?
There are two common ways to filter out which papers to read. First, keyword searching. Great when you know what you’re looking for, poor when semantics drift over time with researchers changing or having multiple names for the same thing through the years. Second, citation chain searching through top cited papers. Sadly, you’ll miss out sometimes on the excellent research by less famous researchers in the field. The method we use at Thinking Machines mitigates these weaknesses and paints a different picture of the trends and directions in the field of artificial intelligence.
We used word embeddings to examine how topic compositions have been changing and how topic directions have been shifting at NIPS over the last 30 years. Our analysis is based on a corpus of 7,241 papers from NIPS proceedings that were published from 1987 to 2017 (30 years).
For the purpose of our analysis, we employed the FastText model for word embedding that allows users to learn text representations and text classifiers and to visualize them into insightful semantic models.
So, how has research in AI evolved over time? What are the key topics you need to know as an aspiring machine learning researcher?
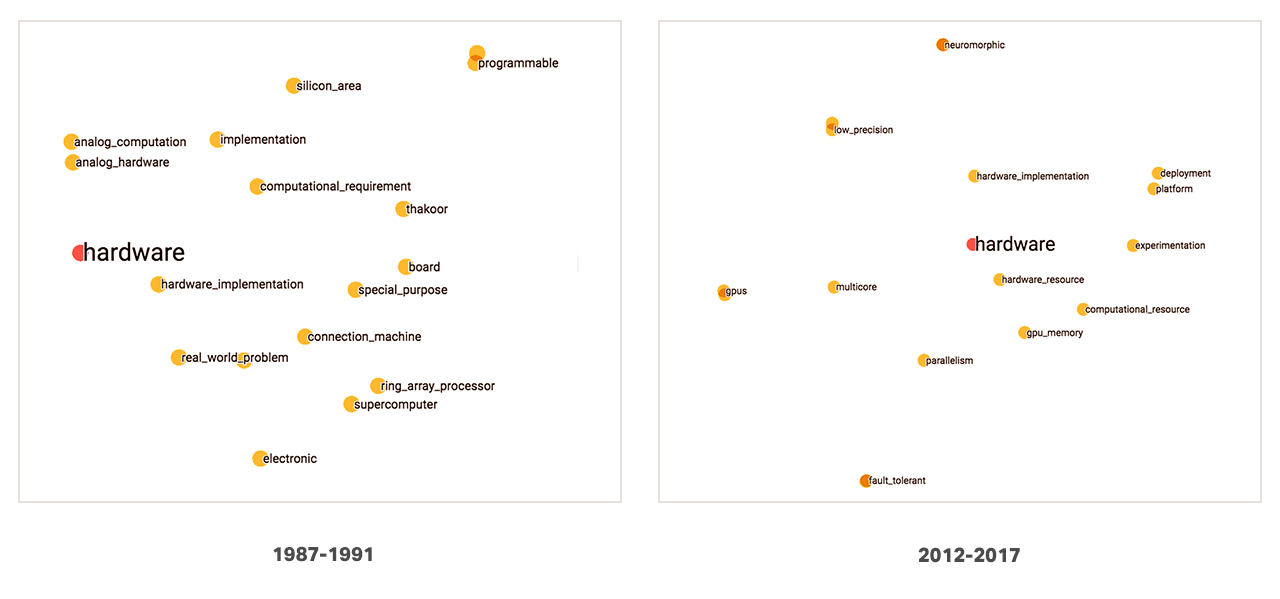
How researchers have been tinkering with their hardware
Well, to start, hardware research does not revolve around analog computation anymore as it did in the 80’s and 90’s. As AI software has become more sophisticated and scaled up, contemporary research on hardware revolves around having powerful state-of-the-art hardware that could accommodate the computational requirements and deployment of architectures like deep learning.
AI research shifted from using traditional computing hardware to parallel systems and graphics processing units (GPUs) over the last 30 years. This shift is apparent in the topic neighborhood of hardware where we see parallelism and gpu being more semantically related to this topic in the deep learning era (2012 - 2017).
Reinforcing reinforcement learning
Reinforcement learning, the branch of artificial intelligence at the core of Google DeepMind’s AlphaGo, has not lost research traction through the years. In its infancy, reinforcement learning dwelled on topics like dynamic programming. Twenty-first century research have been about the topics of markov decision process and multi-agent learning, both important in the development and deployment of optimization applications used in various industries.

The work done with artificial neural networks
Neural networks have been in the spotlight since the great leaps that deep learning methods have yielded in the fields of computer vision and natural language processing in recent years. The concepts have been around since the 1960’s with early research revolving around relatively simple optical and recurrent neural networks. Contemporary research and applications have been focused on the ubiquitous topics of deep learning, pattern recognition, and artificial intelligence.

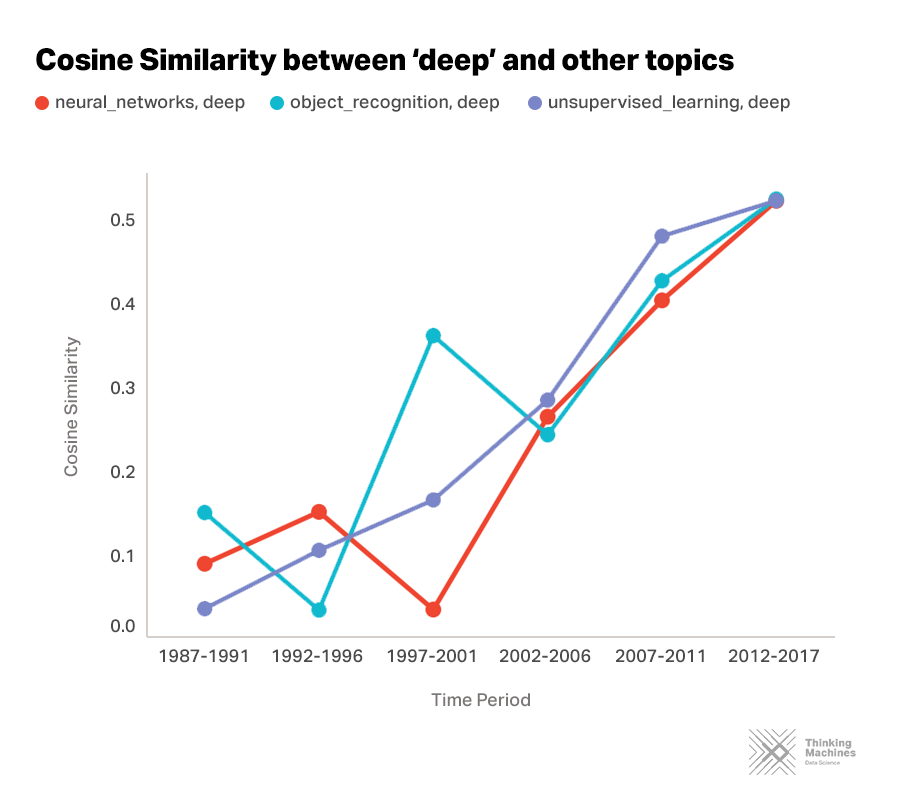
Where do we go from here? Everybody’s doing "deep” research
Neural networks is doing “deep”. Object recognition is doing “deep”. Unsupervised learning is doing “deep”. Everybody is doing “deep”! The resurgence of neural networks in AI research has largely been driven by the introduction of more sophisticated deep architectures, giving birth to research in deep neural networks. The same trend can be seen in object recognition, a fundamental task in computer vision, and in unsupervised learning. Currently, deep learning has risen to be a major research topic for a lot of AI researchers across all disciplines and industries. Research on “deep” will continue to increase until the foreseeable future.
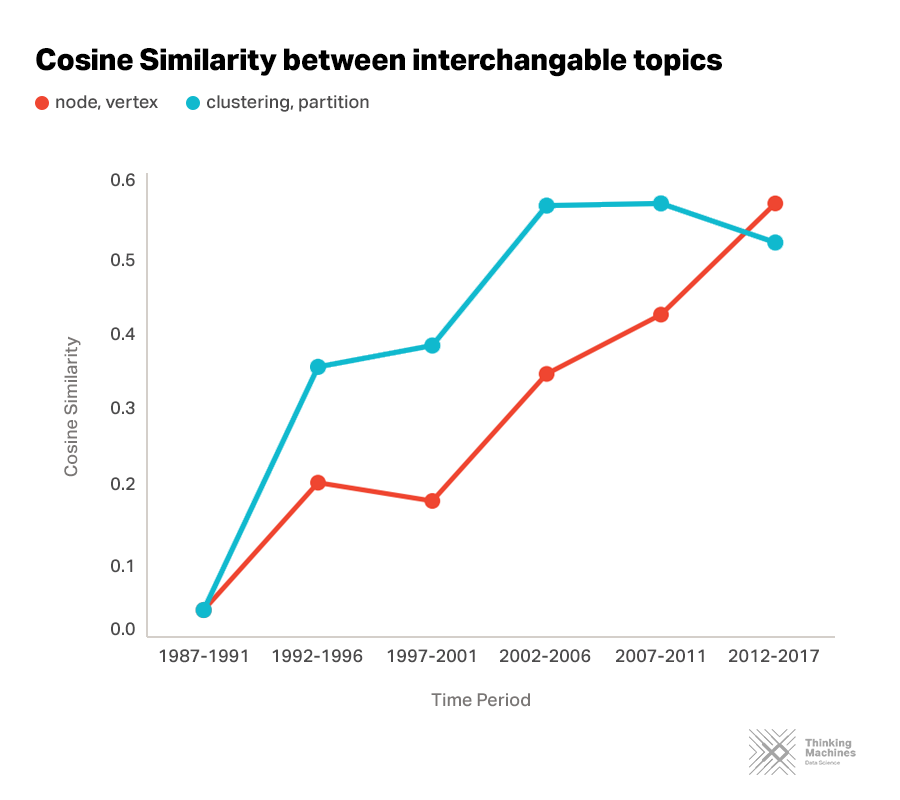
Would a "node" by any other name smell as sweet?
In network science, a “node” and a “vertex” refer to the same thing. This is the same with how “clustering” and “partition” are interchangeable. Semantics could prove to be problematic when it comes to doing research. The method we used allows for us to discover which terms researchers have been using interchangeably and could help in better understanding the AI research landscape.
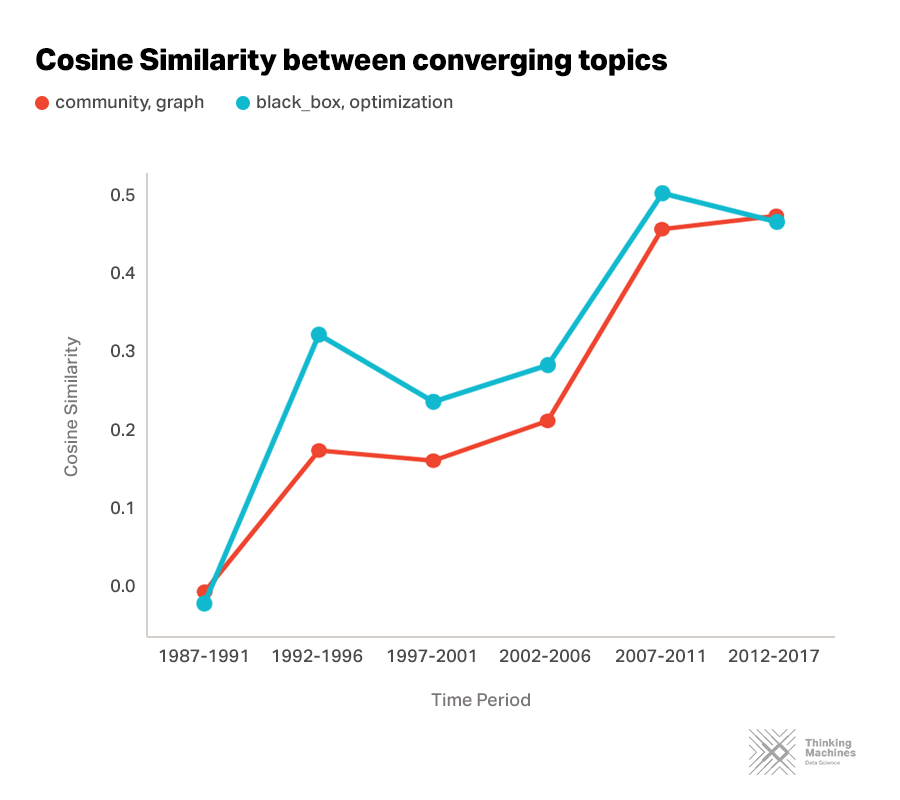
Some topic friendships grow over time
The research direction of certain AI topics can be understood by looking at other topics that are increasingly related to them.
For instance, we can see the study of communities being closely associated to graphs. Most real-word graphs have inherent community structures but such groupings are not often that explicitly defined. The process of automatically detecting communities in a graph has continually been an increasingly active research area in AI.
Moreover, we can see how blackbox and optimization are becoming closely related. Most machine learning techniques that are widely used at present are based on gradient optimization. As we develop more complex machine learning models, blackbox optimization seems to be next ground for learning.
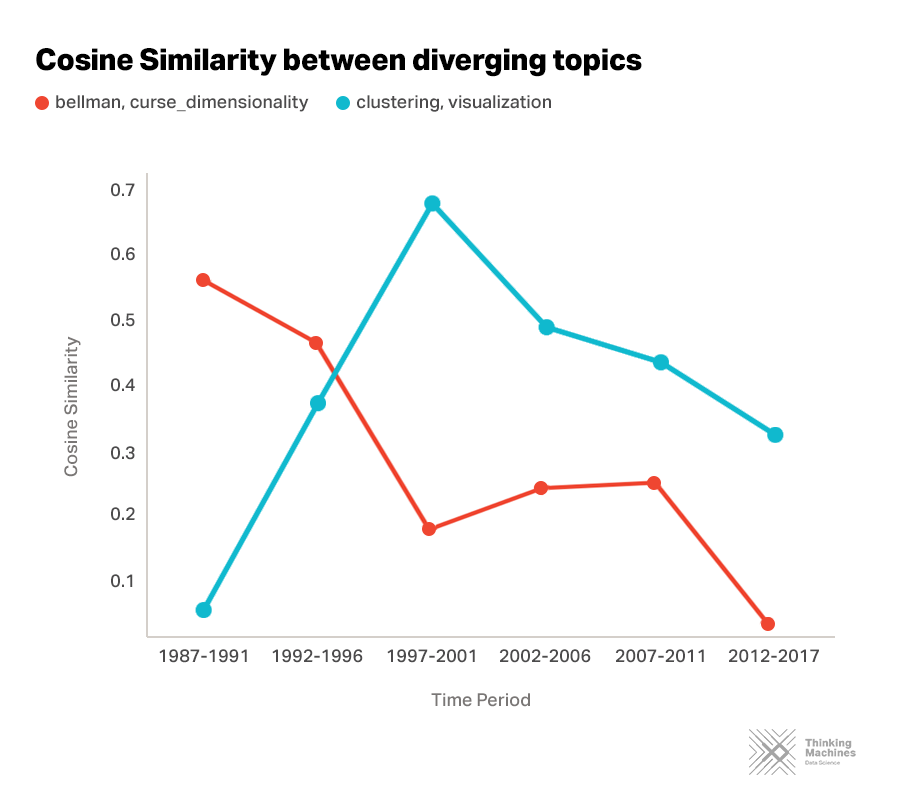
But some topic friendships fade away
As coined by Richard Bellman, the "curse of dimensionality" is the exponential increase in the number of samples needed to estimate a function whose inputs have a higher dimensionality. Essentially, data points represented in high dimension become sparse and renders any clustering of the data points meaningless. Our findings on the drifting of Bellman in the discussion of the curse of dimensionality might suggest that authors have dropped the explicit attribution of the theory to Bellman in their work. That’s the sad reality of creating excellent research. When everybody in the field knows your work, they don’t find it necessary to mention that you wrote it.
Another interesting topical drift can be observed in clustering and visualization. The decreasing similarity of these topics could be attributed to the increasing application of clustering outside of visualization.
Going beyond academic research
The use of word embeddings in analyzing topic dynamics in the AI landscape has provided us insights into how research has developed through the past 30 years. As you could imagine, this technique could be used in all fields of research. Understanding the underlying trends and directions in research in different fields becomes easy using this technique.
Beyond streamlining and making academic research more efficient, we could use the same method in applications outside of academia. In marketing for example, this technique could be applied to understand which words work best to advertise different kinds of products. In retail and e-commerce, word embedding could easily categorize and visualize comments and complaints on products, identifying pain points and possible improvements. There are many more applications for word embedding outside of the mentioned examples. It’s only a matter of having the data, knowing what to do with it, and having the right people for the job.